FAQ
Problems that Predictive Test Selection can solve
Key value proposition: Ship code faster by testing faster
Software development teams are pressured to deliver code faster while maintaining high quality.
There are numerous approaches to help teams deliver code faster: building a CI pipeline, automating tests, and continuously delivering code to production. However, none address the problem that running tests (long or short) is the bottleneck in delivering software.

Launchable's solution is to intelligently prioritize tests to reduce testing times without sacrificing quality. Developers get feedback much earlier in the development cycle. Launchable helps teams ship code faster by testing faster.
Where does Launchable Predictive Test Selection fit into my development pipeline?
Launchable Predictive Test Selection is test agnostic - send data from the test suites that cause the most pain in your delivery cycle. Launchable can help reduce the time it takes to run them - delivering feedback earlier.

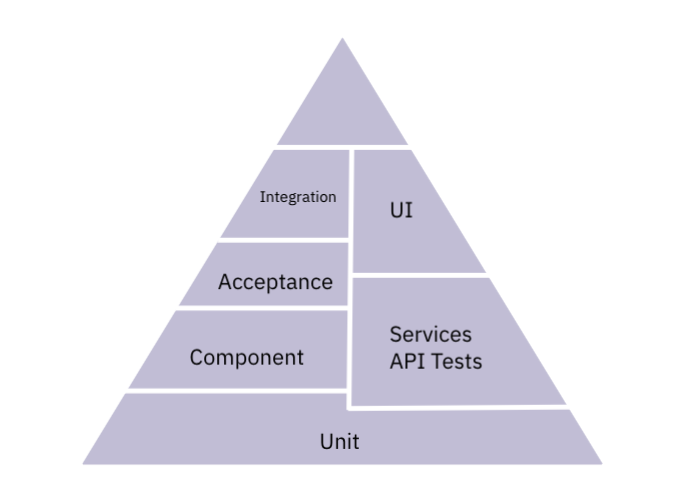
How do I use Launchable Predictive Test Selection to change my testing lifecycle?
You can use Predictive Test Selection for either Shift left or In-place reduction.
Think of Shift left as an approach to test for risks earlier by testing earlier (typically by moving some nightly tests earlier) in your pipeline.
Think of In-place reduction as an approach to provide faster feedback by running fewer tests in one stage (typically, tests run on each git push) by shifting less important tests to a later stage.
Does Predictive Test Selection only work for "greenfield" or "brownfield" applications?
Predictive Test Selection helps in both use cases. Launchable requires that the test suite under consideration runs at a reasonable frequency (multiple times per week versus once a month).
The key question is, "Where are developers seeing pain from long testing times?" The answer tends to be different for different teams. Some teams want to cut down long integration test cycle times (from hours to minutes); this typically is the case in brownfield applications. Others want to cut down unit test cycles for faster feedback to developers (from 30 minutes to less than 5 minutes); this typically is the case in greenfield applications.
The key is to bring Launchable in as early as you can so that you can get the benefit of shipping code faster earlier.
Does Predictive Test Selection work for microservices? Monoliths?
A question with a similar flavor to "greenfield or brownfield applications" with a similar answer. Predictive Test Selection works equally well in both cases and solves similar challenges in both cases.
Monoliths: Teams with monoliths typically use Launchable for the "nightly" test scenario. The team has accumulated a lot of tests over a period of time that cannot be run on every push. These teams look to shift left these nightly tests to provide feedback to developers as early as possible. Some teams use Launchable to help speed up unit or acceptance tests as the number of tests has increased.
Microservices: Unit tests for individual microservices tend to run quickly for most organizations. However, the integration testing scenario remains a challenge (just as with monoliths). Thus, teams typically use Launchable to help with integration testing scenarios. Teams that really care about having a fast dev loop on every git push use Launchable to optimize their unit tests.
Where does Predictive Test Selection not help?
Manual tests: tests where developers test the application by hand.
Tests that run very infrequently: tests must run at least a few times a week to use Launchable.
What is the maturity in testing automation required? Or only some of the tests are automated. Can Predictive Test Selection help?
Yes. No team ever has enough tests or enough testing automation. It is good to start by adding Predictive Test Selection on top of what you already have; this helps improve feedback times early on, and you continue to reap benefits as your automation matures.
Launchable can help in scenarios where automated tests are triggered automatically or manually. Tests need to run on a reasonable frequency, though (think multiple times per week versus once a month).
Launchable's Approach and Impact
What makes Launchable Predictive Test Selection unique?
Launchable is focused on finding the "needle in the haystack" for every change to minimize test execution times. Launchable is based on an exciting Machine Learning based approach being used by Facebook and Google. Predictive Test Selection is a branch of what is commonly known as Test Impact Analysis.
Launchable is democratizing the Predictive Test Selection approach to make it available to teams of all sizes at the push of a button. Without this practice, teams must manually create subsets, "smoke tests," or parallelize their tests. (Note: Launchable speeds up existing smoke or parallelized tests, too.)
What impact can Launchable Predictive Test Selection make?
The key component that helps Launchable learn well is that the test suite should be run reasonably frequently and have some failures. Typically, teams see a 60-80% reduction in test times without impacting quality.
The primary reason that teams like Manba (see case study) use Launchable is that it has enabled the team to ship code faster and push more changes through.
My test runtime went down 90 percent! Deployment to Heroku went from 30 to 10 minutes.
It is great, just great!
Larger teams have focused on improving developer productivity times and increasing software delivery velocity. See case studies of an auto manufacturer and a Silicon Valley Unicorn using Launchable.
Trialing and using Launchable
What is the effort required to add Predictive Test Selection to my team's CI pipeline?
You instrument your build script with four commands.
Send information about the changes being tested
Request a subset of tests from Launchable
Run those tests using your existing tooling
Send information about test failures/successes to train the model
We have built integrations with various test runners to make interacting with Launchable easy. Here is an example of how these commands look when using Maven.

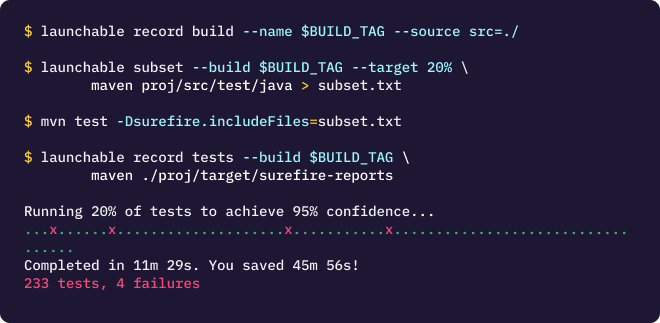
The Getting started with the Launchable CLI guide will walk you through each step in detail.
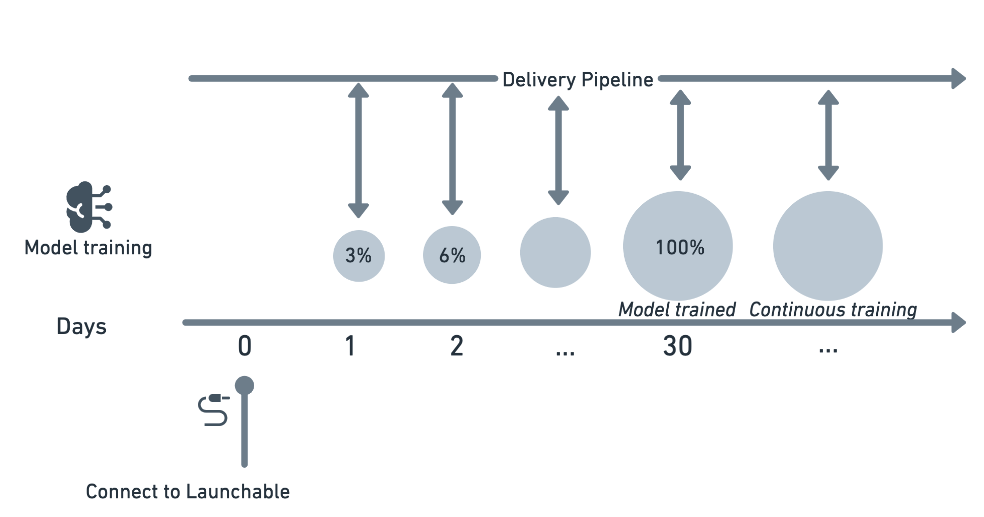
How long does it take to train an ML model?
Typically, it takes about a week to initially train the model for a test suite run with a reasonable frequency and with sufficient failures to learn from. Over time, the model learns more and more.
That said, you can start using Launchable from day 1 using the --observation option in the CLI reference. As the model learns, the subset will start capturing more issues so you can confidently run only the recommended dynamic subsets of tests.

Can you help us add Launchable to our build scripts?
Most teams get going very quickly. However, if you would like us to talk to your team to help with the instrumentation, reach out to our sales team to set up a call. You can also join our Discord community channel.
Can I try Launchable Predictive Test Selection?
Yes. We offer free trials and a free tier for small teams (and open-source projects). If you work at a large company, we can help you through a POC. See more on the pricing page.
Responses to key questions from customers
Customer questions fall into three buckets: testing, machine learning, and security.
Questions about testing
Do I end up testing less with Predictive Test Selection?
Key Idea: You are testing more frequently. In short, the answer is no: teams tend to test more frequently. Because Launchable reduces testing times, you can execute more test runs as a result. The tests in each run are dynamically selected for every code change.
What happens to the tests that are not run? This will surely impact quality!
Key idea: Defensive runs. We ask our customers to view Launchable as a way to speed up tests and ship code faster. The tests that are not run as part of the subset should be run as part of a defensive run. The defensive run captures any tests that escape through the subset. The defensive run is instrumented to send us the test rests, and thus Launchable uses this run (in addition to the subset) to train the model.
Questions about machine learning models
How often is my team's model trained?
Your model is trained several times a week.
Is the model shared between customers?
No. Each model is specific to each customer.
How does the model learn about new code or new tests?
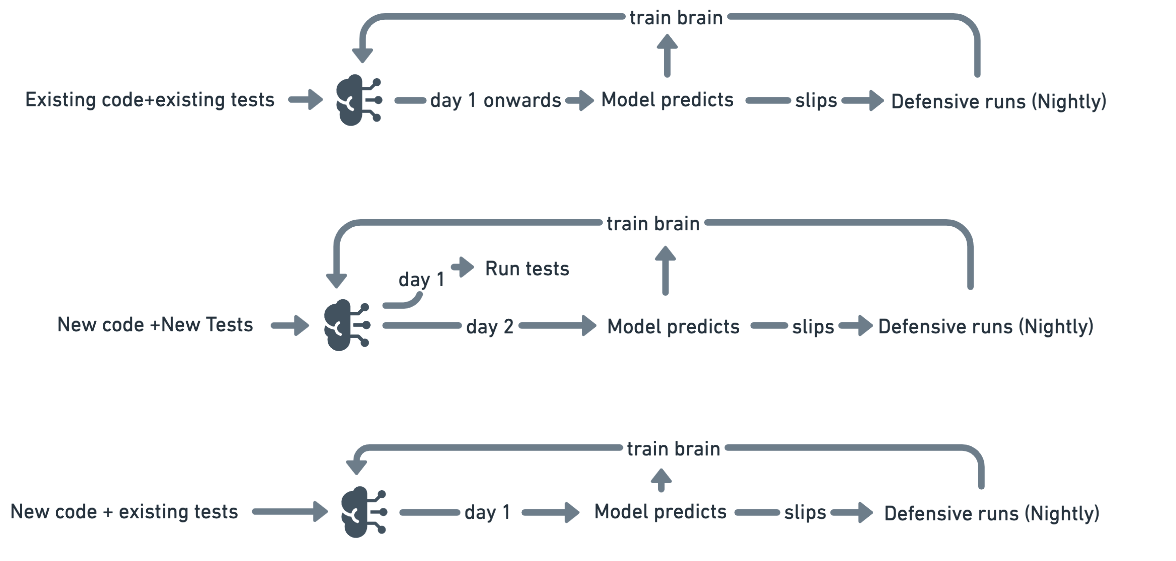
This question covers three scenarios (outlined in the graphic below).
Scenario 1: Existing code and existing tests
This is a "business as usual" scenario i.e., either existing code or existing tests are modified. The model predicts which tests to run and uses the subset results and the defensive runs results to update itself to predict better the next time.
Scenario 2: New code and new tests
This scenario is about when active new development is happening and new tests are added simultaneously. The model sees new tests and schedules them to be run because it doesn't know about them. The model then uses the data from this run and trains itself. From day 2, the model behaves as scenario 1 - initially, it may still get more wrongs than right because the codebase is new. Thus the defensive runs become important to catch any issues that escape and train the model to perform better.
Scenario 3: New code and existing tests
New code is added in this scenario, but developers expect the existing tests to catch the issues. The model predicts the tests as in scenario 1. Note: if existing tests don't test for the new code, the model cannot do much about it - developers will need first to write the test cases to provide enough code coverage.

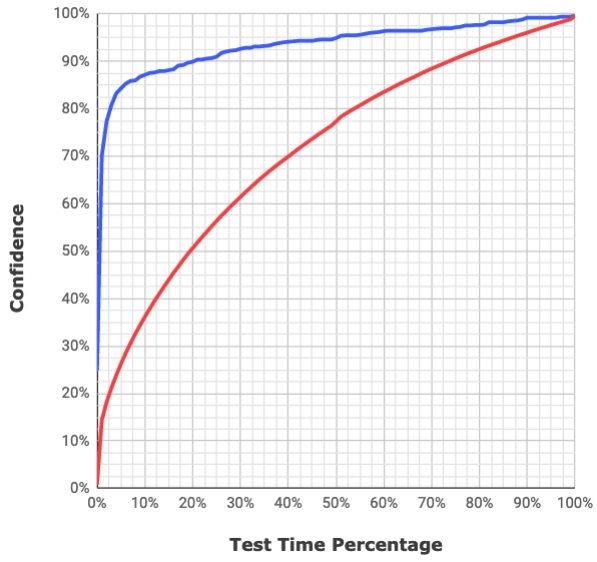
How do you evaluate the performance of a model?
We use a model performance curve. This curve is based on the actual data sent by the customer. We split the data into training and evaluation data to measure the model's performance.
Here, the red line is an actual customer's baseline (without Launchable). The baseline shows that it takes about 75% of tests to get to 90% confidence, where confidence is the likelihood of a failing test run. Thus, this customer finds 90% of failing runs after running 75% of the tests. In their case, the test run was about 1 hour, so the test suite had to run about 45 minutes to get to 90% of issues.
The Launchable model (blue line) could reach the same 90% confidence by running 20% of tests. Thus, the test suite ran for about 10 minutes to find an equivalent number of issues.
If the customer shifted tests left, they could run 10-minute runs multiple times daily and catch most issues. Any laggards would be found in defensive runs.
For this customer, this productivity boost was equivalent to 8 new development resources for the year and 3x hardware impacts!

Concerns about security
For details, see sections: data privacy and protection, security policies, and data examples.
What data is sent to Launchable? Do you look into the code?
Launchable doesn't use code itself to make decisions (this is where our Predictive Test Analysis - ML based approach is superior to static code analysis). The information sent over is the git commit graph or metadata about your source code changes. This metadata includes files changed, the number of lines in the files that have been changed, test names, and their results. Read more in data examples section.
You can also use the --log-level audit global option when you invoke the CLI to view exactly what data was passed in the request. You can also use the --dry-run option to simulate requests. See CLI reference.
Where can I find data privacy and protection policies?
See the data privacy and protection document.
Where is the Launchable SaaS hosted? Is the SaaS multi-tenant?
The SaaS is hosted on AWS and is multi-tenant.
Where can I see Launchable's security policies?
See the security policies document.
Where can I see Launchable's AWS policies?
Contact our sales team to get a copy of our AWS policies.
I still have questions. Can you meet my infosec team?
We're happy to do so. Contact our sales team to help set a meeting with your infosec team.
More questions
Do you sign NDAs?
We have no NDA requirements from our end; these requirements come from the customers. We will work with you if your company requires you to sign an NDA with a vendor. We have our own NDA or can work with your team's NDA.
Before you go down the NDA route, we'd be remiss if we didn't point out the following:
Most small teams (or big) can get started on our free or Moon tier without having to talk to us. So we'd encourage you to explore that option.
We can also meet up for an introduction meeting to figure out if you have to sign an NDA to work with us.
Launchable sounds great! Can I ask you to evangelize my team?
We would love to. We don't want you to own the burden of evangelizing Launchable in your organization. A champion often brings us in to talk to their internal stakeholders. Reach out to sales to set up a meeting.
How can I talk to a human?
We love talking to people that we can help. Reach out to our sales team or jump into our Discord channel.